Lately, I had to convert the encoding of a multimodule maven project from our default Cp-1252 encoding to UTF-8. Changing the project settings is rather easy and there are multiple guides availble on the internet, so I won’t re-invent the hot water.
The most dificult task however was converting all our source files from Cp-1252 to UTF-8 and preferably on Windows 🙂 . I’ve been looking into applications that would auto-convert everything for me, but none of them actually converted to content, resulting in garbage files. I almost started converting all the files by hand using Notepad++ when I discovered this process could be automated !
First of all you’ll need to install the Python Script plugin using the Notepad++ Plugin Manager.Download the Python Script plugin from SourceForge. I’ve had some issues with the version that currently ships through the PluginManager so it’s best to get this version. Then, after installing and restarting Notepad++, you have to create a new script with the following code:
import os;
import sys;
filePathSrc="C:\\Temp\\UTF8"
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] != '.jar' and fn[-5:] != '.ear' and fn[-4:] != '.gif' and fn[-4:] != '.jpg' and fn[-5:] != '.jpeg' and fn[-4:] != '.xls' and fn[-4:] != '.GIF' and fn[-4:] != '.JPG' and fn[-5:] != '.JPEG' and fn[-4:] != '.XLS' and fn[-4:] != '.PNG' and fn[-4:] != '.png' and fn[-4:] != '.cab' and fn[-4:] != '.CAB' and fn[-4:] != '.ico':
notepad.open(root + "\\" + fn)
console.write(root + "\\" + fn + "\r\n")
notepad.runMenuCommand("Encoding", "Convert to UTF-8 without BOM")
notepad.save()
notepad.close()
I think the code speaks for itself, just be 100% sure that you do the conversion to UTF-8 without the UTF-8 byte order mark (BOM) since javac does not support this special character.
If you have problems running the script, then first open the console (Plugins > Python Script > Show Console). Chances are that the indents got messed up (for those who don’t know Python, it doesn’t use curly brackets to identify a code block, it uses correct indentation instead).
//Update 20/07/2017:
This post is still attracting a lot of attention and for some people things work fine and for some it doesn’t. I would strongly advise to read through the comments in case you have a problem. I just re-tested the script on my laptop with Windows 8, Notepad++ 7.4.2 and PythonScript 1.0.8 and it works like a charm.

Reblogged this on Sutoprise Avenue, A SutoCom Source.
How do you run the script?
You first have to create the script via “Plugins > New Script”, then it’ll be available in the menu:
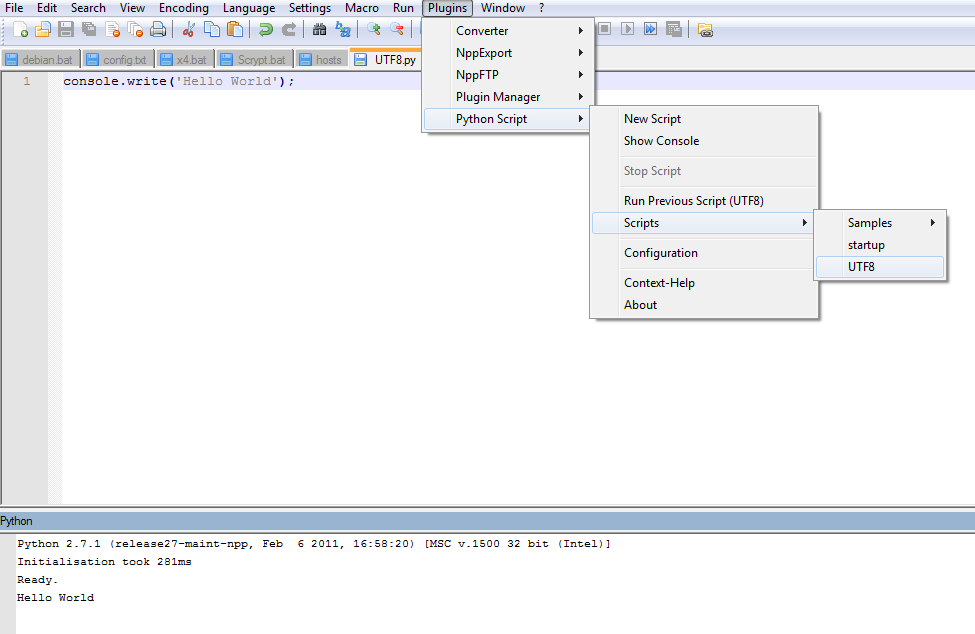
Hi. I’ve downloaded and installed PythonScript_1.0.8.0.msi and I’m trying to use the v7.4.2 version (64) but I do not see “Python script” sub-menu. Is it normal ?
No, have you tried downloading the ZIP and extracting it to the NPP folder ?
In case someone runs into this problem as well. I had to move the folder out from upper level folder that had umlauts in its’ name to get it to work.
I would not recommend do it this way:
if fn[-4:] != ‘.jar’ and fn[-5:] != ‘.ear’ […]
The script could modify any files which is not in the != list
In my case, it found my .git directory and messed up my local repository.
You should rather type in what kind of file extensions you want to modify.
In my case
if fn[-4:] == ‘.php’
That might also work. I used the inverse match because of the large diversity of filetypes we have in our projects.
Great post.
The strange thing is, that if you use a “localized version” of notepad++ you should adapt the runMenuCommand.
German Example: notepad.runMenuCommand(“Encoding”, “Konvertiere zu UTF-8”)
Even if “Encoding” is still english, it only worked for me after using the german Menu.
You save my live !!
I get the error .
https://www.dropbox.com/s/f2efnzt9cd2i5or/%E5%B1%8F%E5%B9%95%E6%88%AA%E5%9B%BE%202014-05-31%2015.59.03.png
Looks more like an encoding issue in Notepad++ or the Python plugin. I’d say, try to contact those developer as I can not help you with this issue.
Hi, htanks for the wisdom
I get this error:
File “C:\Users\user\AppData\Roaming\Notepad++\plugins\Config\PythonScript\scripts\convertutf8.py”, line 5
for fn in files:
^
IndentationError: expected an indented block
In Python, indentations have the same meaning as curly brackets in many other languages. Make sure the indentation is exactly the same as in this post (and make sure it are tabs and not spaces)
Ok, tried everything (with / without tabs on every lines) but no changes, strange thing.
Is there any way you can embed the code as it stays the same from copy to paste?
Bless
Sorry, seems like the indentations went missing. Post adapted, source should work again.
Indeed, thanks Boss 🙂
For me, NotePad++ is like doing nothing 😥 Nothing in the console, nothing converted 😥
Can you give some more infomation ? Some screenshots maybe ? Maybe I can help ?
When I click to my script in order to run it, nothing happen 😦 I have anything in the console and nothing is converted. It’s like nothing occured 😦
Did you change the ‘filePathSrc’ variable to match your source directory ?
Oh actually, I solved my problem.
I didn’t use the New Script Option Using this New Script Option, everything works perfectly ! And as laczkour said, I prefer to use == ‘.java’ than something, but this script does really well the job, Thank you !
Using this New Script Option, everything works perfectly ! And as laczkour said, I prefer to use == ‘.java’ than something, but this script does really well the job, Thank you !
Thx a lot! U are my guest for a Beer 😉
I adapted the example (paths and file types modified) and tried running it after installing Python Script.
All I got was a runtime crash in Notepad++ .
It seems that the plugin is immature, and the documentation is lousy.
I converted 4 maven project with about 150000 lines of code and had no issue at all. Maybe the plugin doesn’t work with the latest Notepad++ version. You could try the powershell alternative : http://stackoverflow.com/a/24481910
Awesome script, thank you very much for sharing it! I would like to add some comments with my experiences:
– Python script plugin did not work me if I installed through the Plugin Manager. (I use Np++ 6.6.6 on Win 8.1 x64). I downloaded the MSI installer from the plugin’s developer site http://npppythonscript.sourceforge.net/download.shtml and it worked well
– First it seemed to run OK, but when I checked my files I realized that nothing happened. I made some tests and found out that the script did not recognize the command. I tried the english and local (Hungarian) version of the command as well, neither worked. Finally I changed the language of Np++ to english and I worked well with the english command. The Hungarian has special characters, probably it caused the problem.
henri
using notepad++ 6.5.5 and npppythonscript 1.0.8.0 full 7zip
it worked,
but with 1.0.6.0 from plugin manager it throw a runtime error
Same thing here!!
Thanks! The only thing about fn[-5:] != ‘.ear’, this should be -4: I suppose 🙂
I’m new to Python, I ran the same thing, but i don’t see the encoding changed to UTF -8.
Plugins–>Python Script–> Scripts–>myfile, when i did this nothing is happening.
I see nothing on the console.
Update on this.. Code is running, but it says.. “NameError: name ‘notepad’ is not defined”
I think i need import some Notepad++ dll i guess. Could you help me with this?
Strange, maybe they’ve changed the API in the latest version. I’ll try to have a look at it this weekend.
I’ve updated my NPP to v6.8.1 and the Python script plugin is at version 1.0.6.0 and it’s working perfectly fine from within NPP. I have no idea why it’s not working for you, maybe try reinstalling NPP and the Python plugin ?
I have, in C: Temp, folder and subfolder more
In each folder and subfolders are more * .html files that have encoding “windows-1250” or “UTF-8 with BOM”
I need a script to Notepad ++, which will in a single action do convert encode to UTF-8
I have Notepad ++ 6.8.1 and I installed Python script plugin
Can you help me
This script will do exactly, you just need to change the path in the script
Saved me tons of time, thanks a lot!
If you run into exception while trying to show the Python console or running the script you have to install the FULL newest version of the Python plugin!
Thanks a lot.
This is exactly what I was looking for and it worked fine for me.
Hi Philip,
Thanks man for the powerfull script you shared with us 🙂
This is my tuned version which worked for me on windows 7 pro 64bit, I share it with the community:
N.B: I list files to be converted rather then exclude those which not should be converted as laczkour suggested, because, it is the safest way.
import os;
import sys;
filePathSrc=”E:\\vhosts\\ticket_support\\191\\bataille”
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] == ‘.php’ or fn[-6:] == ‘.phtml’ or fn[-4:] == ‘.htm’ or fn[-5:] == ‘.html’ or fn[-3:] == ‘.js’ or fn[-4:] == ‘.css’ or fn[-4:] == ‘.txt’:
Notepad.open(root + “\\” + fn)
console.write(root + “\\” + fn + “\r\n”)
Notepad.runMenuCommor(“Encoding”, “Convert to UTF-8 without BOM”)
Notepad.messageBox(‘Project successfully converted to UTF-8 boss’, ‘Converting current project to UTF-8’, 0)
Notepad.save()
Notepad.close()
Thanks one more time 🙂
Thanks… Somebody knows how convert ascii to utf-8? The command to do it.
Does it also takes care if the existing encoding of the file is unknown?
I have no idea, but you can always test it by hand in Notepad++ by opening the file and converting it to UTF-8 and check the result 😉
Firstly, Thank you TamasToth (3:18 PM on 12/16/2014) for providing this reference “Python script plugin did not work me if I installed through the Plugin Manager. (I use Np++ 6.6.6 on Win 8.1 x64). I downloaded the MSI installer from the plugin’s developer site http://npppythonscript.sourceforge.net/download.shtml and it worked well”. I had the same problem. After installing from your provided link, my Python Script worked greatly.
Secondly, for the author of this article. Using
Notepad.runMenuCommor(“Encoding”, “Convert to UTF-8 without BOM”)
didn’t work. I used
Notepad.runMenuCommor(“Encoding”, “Convert to UTF-8”)
Lastly, I have some references for people interested.
http://stackoverflow.com/questions/7256049/notepad-converting-ansi-encoded-file-to-utf-8
http://www.joelonsoftware.com/articles/Unicode.html
All in all, I find this WordPress very useful. Thank you Phillip for writing this article.
Thank you very much ! It may be possible that notepad changed the name of the menu item causing it to stop work. However, for Java projects you may not use UTF-8 with the byte order mark because it will fail at compilation time (at least on Java 6).
Its my first time using python, so forgive me if the question is sily, but I have error:
“Traceback (most recent call last):
File “f:\! rapid\utf.py”, line 7, in
notepad.open(root + “\\” + fn)
NameError: name ‘notepad’ is not defined”
I run it with idle.py as showed here: https://www.youtube.com/watch?v=sJipYE1JT38
Thank you so much. But in notepad++ 6.9.1 and Pythonscript 1.0.8.0 we have to put “Convert to UTF-8” only. it work for me for converting files in utf-8 without bom.
Thanks again.
Thank you for this very useful script. It helps a lot.
However, I met a problem : when a .txt filename contains accent (for example a e acute), the conversion failed.
Does someone already got this situation ?
Is it possible to convert the content of the txt file to UTF-8 but to leave the filename intact ?
Ps : Im running under Windows 10, 64bit.
Thanks in advance
Beter late than never I guess 🙂
This dirty hack works: notepad.open(root + “\\” + fn.decode(“Cp1252”).encode(‘utf-8’))
It worked perfectly for me. Thanks
When I want to run it, and click on the “scripts” nothing appears. How can I fix this problem?
Thank you
I am running Notepad v6.9.2.
I have the already mentioned problem, that by clicking
Plugins->Python Script->Scripts->Convert.py
Absolutely nothing happens at all. I have included a “console.write(‘Test’) at the beginning, but it actually does not show up on execution.
On an additional note, I have Python 2.7 installed on the machine.
Any Help would be welcome.
Hi, thanks a lot. Just want to add that this doesn’t work with the latest “Python Script” plugin for Notepad++. You have to use Python Script version 1.0.8.
Thanks AP. I updated the post to make sure people get 1.0.8 from SF instead of using the broken version from the PluginManager.
Hello,
I’m looking for a way to limit the depth of os.walk method. I want to apply the conversion to HTML files located in the first level only, excluding those in subdirectories.
Can someone help on this? Thanks.
import os;
import sys;
Path=”C:\\python-test”
for root, dirs, files in os.walk(Path):
for filename in files:
if filename[-5:] == ‘.html’:
notepad.open(root + “\\” + filename)
console.write(root + “\\” + filename + “\r\n”)
notepad.runMenuCommand(“Encodage”, “Convertir en UTF-8”)
notepad.save()
notepad.close()
OK, I found 2 solutions for my problem, both need to be added below os.walk(Path)
—
for root, dirs, files in os.walk(Path):
if root == Path:
—
OR
—
for root, dirs, files in os.walk(Path):
nested_levels = root.split(‘/’)
if len(nested_levels) > 0:
del dirs[:]
—
Sorry, I did a mistake inside the second solution, it should be :
—
nested_levels = root.split(“\\”)
if len(nested_levels) == 2:
—
oh cool, thanks for sharing
Thank you for sharing, awesome job.
Two notes for my usage that others may find handy:
I had to install Python plugin through msi installer as well.
Changed Convert to UTF-8 without BOM to Convert to UTF-8 as it didn´t work.
Just be carefull with the BOM because javac doesn’t like it (at least this was an ‘issue’ in Java 6, not sure if Java8 can’t handle the BOM)
Thanks so much! In my case, for the code to work I did some modifications. This is what I used:
import os;
import sys;
filePathSrc=”C:\\Users\\Roberto\\Documents\\Website\\Try2″
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] == ‘.txt’ or fn[-4:] == ‘.php’:
notepad.open(root + “\\” + fn)
console.write(root + “\\” + fn + “\r\n”)
notepad.runMenuCommand(“Encoding”, “Convert to UTF-8”)
notepad.save()
notepad.close()
Hi What version notepad++ and PythonScript version do you use ??
I use notepad++ 6.5 and PythonScript_0.9.2.zip on Window 10 . When i run my python script ,it issue error: NameError: name ‘notepad’ is not defined
Can you tell version notepad++ and down url link , ths
Hey Jerico, I just update the original post. I’ve tested the script and it works with Notepad++ 7.4.2 and PythonScript 1.0.8 . Don’t use the PythonScript version from the PluginManager but instead get it directly from SF: https://sourceforge.net/projects/npppythonscript/files/Python%20Script%201.0.8.0/
This really helped me – thank you!
Hi guys, thank for the useful piece of code. I upgraded this scrip a bit, so that it prompts for the path to the folder where files are and can be canceled. Tested on Notepad++ v7.2.1.
https://pastebin.com/vfQN5kRS
import os;
import sys;
filePathSrc = notepad.prompt(‘Enter the path to the folder where the files are located’, ‘Convert files to UTF-8’, ‘C:\\Temp\\UTF8’);
if filePathSrc is not None and len(filePathSrc) >= 4:
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] == ‘.php’ or fn[-4:] == ‘.htm’ or fn[-5:] == ‘.html’:
notepad.open(root + “\\” + fn)
console.write(root + “\\” + fn + “\r\n”)
notepad.runMenuCommand(“Encoding”, “Convert to UTF-8”)
notepad.save()
notepad.close()
Thx so much!
You saved a lot of time!
So.. can i ignore some directory like a “.git” while looping?
Thx!
Probably by adding something like:
if fn != ‘.git’
Works perfect! Thank you!
This still works great, thank you very much! I’m applying it on a directory with 33k+ badly UTF-8-encoded, very strange xhtml-files which contain chinese characters… All powershell scripts I’ve tried seem to break those (badly encoded) chinese characters – I also checked with big5 and many other encodings, but this kind of odd notepad++ solution was the only option for my project. *thumbsup*
This:
fn[-5:] != ‘.ear’
Should be:
fn[-4:] != ‘.ear’
Maybe here is the focus of some problems.
Phillip,
I’ve tried using PythonScript_1.0.8.0.msi and PythonScript_Full_1.0.8.0.zip from https://sourceforge.net/projects/npppythonscript/files/Python%20Script%201.0.8.0/. With the .msi, it seems to go through the process of installing, but the plug-in does not appear in the Notepad++ Plugins menu. With the .zip, I extract the files and copy them to C:\Program Files (x86)\Notepad++, but again the plug-in does not appear in the Notepad++ Plugins menu. Any ideas? I’m running Windows 7 (64-bit) and Notepad++ v7.6 (32-bit).
Thanks, Josh
Still works 🙂 Thanks!
Same script to convert *currently opened tabs* (and not some preset folder) to UTF8, you need to set Notepad++ language to English.
for filename, bufferID, index, view in notepad.getFiles():
console.write( filename + “\r\n”)
notepad.activateIndex(view, index)
if not notepad.runMenuCommand(“Encoding”, “Convert to UTF-8”):
notepad.messageBox(“Convert to UTF-8 -> Not found (set NotePad++ language to English) \r\n”, “Command not found”)
console.write( “Convert to UTF-8 -> Not found (set NotePad++ language to English) \r\n”)
break
notepad.save()
notepad.reloadCurrentDocument()
Really useful thank you.
One thing that may help beginners like me in Python:
Use fn[-4:] != ‘.php’ because the length of the extension (with the dot) is 4
but
Use fn[-5:] = ‘.html’ because the length of the extension (with the dot) is 5
Hey there,
I am trying to convert csv files in format utf-8 to utf-8 without boom. My code does not procude any errors however the saving does not seem to work.
Suggestions are highly appreciated:
import os;
import sys;
filePathSrc=”D:\\EigeneDateien\\Projekte\\AT\\SteyrArms\\Converter”
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] == ‘.csv’ :
notepad.open(root + “\\” + fn)
console.write(root + “\\” + fn + “\r\n”)
notepad.runMenuCommand(“Encoding”, “Convert to UTF-8 without BOM”)
notepad.save()
console.write(“Done: ” + fn + “\r\n”)
notepad.close()
Kind regards
Bernhard